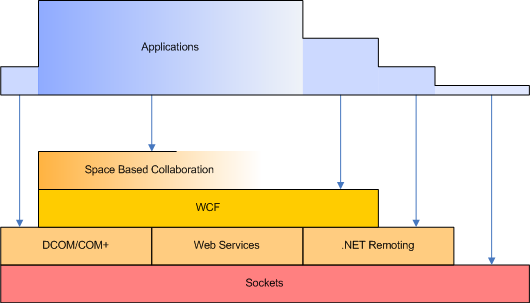
Wer was Neues lernen will, tut das am besten zunächst mit Übungen. Chirurgen lernen neue Techniken erst an toten und/oder nicht menschlichen Lebewesen, Piloten lernen im Simulator. Und ich will den neuen Application Space ausprobieren oder allgemeiner asynchrone und verteilte Architekturen üben. Was sind aber Übungsaufgaben, an denen ich mich versuchen kann? Einen asynchronen und verteilten Service aufzusetzen ist ja trivial. Von dem Service dann auch noch Notifikationen zu bekommen oder Pub/Sub einzurichten, das ist auch trivial. Jeweils für sich genommen sind diese Dinge einfach - aber wie füge ich diese Bausteine zu etwas Größerem, Realistisch(er)em zusammen? Erst in einem umfassenderen Szenarion, das nicht von der Technik ausgeht, sondern von "Kundenanforderungen" kann ich auch feststellen, was einer Technologie wie dem Application Space noch fehlen mag (oder wo sie besonders geeignet ist).
Hier möchte ich nun einige Szenarien zusammentragen, die mir als Übungen für Verteilung und Asynchronizität erscheinen. Sie sind mehr oder weniger komplex, aber immer irgendwie "zum Anfassen". Jedes bietet für die zu übende oder evaluierende Technologie eine andere Herausforderung. Ich werde sie mit dem Application Space implementieren, wer mag, kann aber natürlich WCF pur oder mit Azure oder Jabber pur oder MassTransit oder NServiceBus oder Rhino Service Bus oder MSMQ pur oder TCP Sockets pur oder noch ganz andere Technologien damit ausprobieren. Ganz im Sinne der School of .NET Diskussion sehe ich diese Szenarien auch als Chancen für ganzheitliches Lernen. Clean Code Development, Komponentenorientierung, .NET Framework Grundlagen, TDD... all das und mehr kann man auch einfließen lassen.
Szenario 1: Stammdatenverwaltung
Aller Anfang sollte einfach und typisch sein. Deshalb ist mein erstes Szenario eines, mit dem viele Entwickler immer wieder konfrontiert werden: die Stammdatenverwaltung oder "forms over data". Ein Anwender verwaltet mit seinem Client Daten in einer Datenbank mit den üblichen CRUD-Funktionen: Create, Read, Update, Delete. Zusätzlich kann er einen serverseitigen Datenimport anstoßen.
Ob sich für dieses Szenario eine Verteilung überhaupt lohnt, sei einmal dahingestellt. Allemal, wenn aus anderen Gründen eine Anwendung verteilt werden soll, muss auch die Stammdatenverwaltung auf eine solche Architektur abgebildet werden.
Um das Datenmodell einfach zu halten, reicht es aus, wenn das Szenario sich nur um Personen mit ihrer Adresse dreht.
Datenmodell:
- Person(Nachname, Vorname, Straße, PLZ, Ort, Land, Tel, Soundex)
Featureliste:
- Der Anwender kann nach Personen suchen; der Server liefert eine Liste von passenden Personen zurück.
- Der Anwender kann eine gefundene Person bearbeiten und speichern.
- Der Anwender kann eine neue Person anlegen.
- Der Anwender kann eine Person löschen.
- Der Anwender kann gefundene Adressen in eine CSV-Datei exportieren. Der Export kann clientseitig erfolgen.
- Der Anwender kann den Import von Personen aus einer CSV-Datei veranlassen. Dazu muss er dem Server mitteilen, in welcher Datei die Daten liegen. Der Server importiert, meldet zwischendurch den Fortschritt und liefert am Ende ein Importresultat.
- Dublettenprüfung: Jede Person soll nur einmal in der Datenbank stehen. Mehrere Sätze mit denselben Daten sind zu vermeiden, um bei Mailings nicht mehrere Briefe an dieselbe Person zu senden. Um den Vergleich von Personen zu vereinfachen, können sie mit einem Soundex-Wert ausgestattet werden. Wannimmer eine Person gespeichert werden soll (nach Bearbeitung, nach Neuanlage, beim Import) und schon mit einem anderen Datensatz in der Datenbank vertreten ist, wird die Operation verweigert und der Anwender informiert. Die Dublettenprüfung kann in Schritten implementiert werden:
- Dubletten bei Neuanlage prüfen
- Dubletten beim Import prüfen
- Dubletten nach Bearbeitung prüfen
Klingt doch einfach, oder? Hat aber natürlich seine Tücken, denn es gilt ja, diese Funktionalität asynchron und verteilt zu realisieren. Wie kommunizieren Client und Server im Sinne einer solchen Stammdatenverwaltung miteinander?

Herausforderungen:
- Wie werden asynchrone Operationen wie Speichern oder Import im UI repräsentiert?
- Wie meldet der Server den Fortschritt beim Im/Export an den Client (Notifikationen)?
Szenario 2: Referentenfeedback (Heckle Service)
Christian Weyer hat ein schon älteres Szenario in seinem dotnetpro-Artikel "Schnuppern an Azure" (5/2009)mit den aktuellen Technologien neu implementiert. In der dotnetpro 7/2009 greife ich das auf und realisiere es mit dem Application Space.
Die Idee ist einfach: Zuschauer eines Vortrags auf einer Konferenz sollen dem Referenten live Feedback geben können. Sie sollen sozusagen elektronisch zwischenrufen können (engl. to heckle). Dazu hat jeder Teilnehmer einen Client, mit dem er kurze Textnachrichten an den Referenten senden kann, der sie in einem eigenen Frontend auflaufen sieht.
Datenmodell:
- Nachricht(Absendername, Nachrichtentext, Eingangszeitstempel) - Jede Nachricht gehört natürlich zu einem Referenten. Ob das allerdings in der Nachricht vermerkt werden muss, soll hier nicht festgelegt werden.
Featureliste:
- Teilnehmer senden Zwischenrufe an den Referenten.
- Teilnehmer sehen sich die Liste der letzten n Zwischenrufe an.
- Der Referent bekommt jeden Zwischenruf automatisch angezeigt.
- Falls der Referent sein Frontend - aus welchen Gründen auch immer - neu startet, bekommt er die Liste aller bisher eingegangenen Zwischenrufe angezeigt.
- Der Referent identifiziert sich irgendwie, so dass die Teilnehmer ihm und keinem anderen ihre Zwischenrufe senden. Die Teilnehmer müssen einen Referenten also beim Zwischenrufen adressieren. Potenziell kann die Heckle-Anwendung ja gleichzeitig in vielen Vorträgen zum Einsatz kommen.
- Der Veranstalter der Vorträge kann die Zwischenruflisten aller Referenten jederzeit einsehen.

Herausforderungen:
- Wie nehmen Teilnehmer mit dem Referenten Kontakt auf? Direkt, indem sie seinen Rechner adressieren oder indirekt via eines Discovery-Servers?
- Wo werden die Nachrichten vorgehalten, damit vor allem Teilnehmer und Veranstalter sich jederzeit einen Überblick verschaffen können?
- Wie wird insb. der Referent automatisch über neue Nachrichten informiert?
Szenario 3: Tic Tac Toe
Es ist zwar kein typisches Geschäftsanwendungsszenario, aber es macht Spaß: ein Spiel realisieren. Bei Tic Tac Toe (TTT) sind die Regeln simpel, so dass man sich auf die verteilte Implementation konzentrieren kann.
Zwei Spieler spielen gegeneinander auf einem TTT-Brett. Jeder sitzt an seinem PC und sieht den gemeinsamen Spielstand.
Datenmodell:
- Spielfeld mit 3x3 Spielfeldern in den Zuständen O, X und leer. Zusätzlich sollte das Spielfeld noch einen Spielzustand haben wie Spiel begonnen, Spiel beendet, Gewinner ist Spieler 1, Gewinner ist Spieler 2.
Featureliste:
- Ein Spieler bietet sich zum Spiel an.
- Ein Spieler nimmt Kontakt mit einem anderen auf und sie beginnen eine Partie.
- Spieler machen Züge.
- Ob und welcher Spieler gewinnt, wird automatisch festgestellt.
- Ein Spieler beendet eine Partie vorzeitig.
Dies ist während des Spiels natürlich ein Peer-to-Peer-Szenario. Ob intern die Rollen aber auch gleich sind oder nicht vielleicht doch ein Spieler ein Partienserver ist, hängt von der Implementation ab.

Herausforderungen:
- Wie nehmen die Spieler Kontakt miteinander auf?
- Wo wird der Partienzustand gehalten?
- Wie erfahren die Spieler über den nächsten Zug?
- Wie wird den Spielern das Spielende mitgeteilt?
Szenario 4: Starbucks
Gregor Hohpe hat in einem Blogbeitrag deutlich gemacht, wie wenig praktikabel die bisher so beliebten 2-Phase-Commit-Transaktionen in der realen Welt, d.h. in asynchronen (und verteilten) Szenarien sind. MassTransit und Rhino Service Bus haben das aufgenommen und versucht, mit ihren Mitteln das Szenario abzubilden. Es ist einfach eine schöne Fingerübung für jeden, der in die verteilte und asynchrone Programmierung einsteigen will.
Bei Starbucks kommen Kunde, Kassierer und Barista zusammen. Der Kunde bestellt ein Getränk, der Kassierer nennt den Preis und nimmt das Geld entgegen. Währenddessen bereitet der Barista schon das Getränk zu und serviert es, wenn die Zahlung geklappt hat.
Datenmodell:
- Bestellung(Getränkeart, Bechergröße, Menge)
- Zahlungsaufforderung(Gesamtpreis einer Bestellung)
- Bezahlung(Betrag, Zahlmittel) - Zahlmittel könnten Barzahlung oder Kreditkarte sein
Featureliste:
- Kunde bestellt ein Getränk beim Kassierer. Variation: Kunde bestellt mehrere und verschiedene Getränke beim Kassierer.
- Kassierer nennt den Gesamtpreis
- Kunden bezahlt
- Kassierer nimmt Bezahlung entgegen und prüft den Betrag. Wenn ok, dann schließt er die Bestellung ab.
- Barista bereitet bestellte Getränke vor.
- Wenn Bezahlung abgeschlossen, stellt der Barista die Getränke zur Abholung bereit.
Der Kunde kann hier als interaktiver Client realisiert werden. Kassierer und Barista hingegen sind automatische Dienste. Um die reale Welt nachzustellen, können ihre Funktionen über Pausen (Thread.Sleep()) eine wahrnehmbare Dauer bekommen.

Herausforderungen:
- Wie nehmen die Beteiligten Kontakt miteinander auf?
- Wie wird der Dialog zwischen Kunde und Kassierer geführt?
- Wie erfährt der Kunde über das fertiggestellte Getränk?
- Was passiert mit einem schon zubereiteten Getränk, wenn die Zahlung nicht erfolgreich ist?
Szenario 5: Arbeitsteilung
Das MSDN Magazine Juni/2009 beschreibt in "A Peer-To-Peer Work Processing App With WCF" ein Szenario, dass sich auch zur Übung zu realisieren lohnt. Mehrere sog. Worker stehen da bereit, um Aufträge von sog. Usern anzunehmen. Der Artikel nutzt zur Arbeitsverteilung das P2P-Protokoll von WCF - aber man kann es auch anders machen.
Datenmodell:
- Arbeitsauftrag(Id, Dauer)
Featureliste:
- User vergeben Aufträge in einen Pool von Workern hinein.
- Worker übernehmen einen oder mehrere Arbeitsaufträge.
- Worker können dem Pool beitreten oder ihn verlassen.
- Ob ein Worker Aufträge annimmt hängt von seiner Last ab. Die gesamte Auftragslast soll natürlich möglichst gleichmäßig auf die Worker verteilt werden.
- Wie die Arbeit "so läuft" können sog. Spectators beobachten; sie dienen der Instrumentierung des Systems.
In dieser Featureliste fehlen einige Aspekte, die der Artikel beschreibt, z.B. "Work Item Backup" oder "Work Sharing". Ich habe sie nicht aufgenommen, weil sie mir abhängig scheinen vom gewählten Lösungsweg (hier: P2P-Kommunikation). Meine Szenarien sollen aber keine Lösungswege oder Technologien nahelegen (z.B. Einsatz eines Busses oder Sagas oder P2P-Kommunikation).
Die schlanken Aufträge habe ich ebenfalls deshalb übernommen. Es geht ja nicht um eine konkrete Problemdomäne. So müssen die Aufträge nur eine Dauer haben, um Lastverteilung beobachten zu können.

Herausforderungen:
- Wie wird die Auftragslast möglichst gleichmäßig (oder "gerecht") auf die Worker verteilt?
- Wie werden weitere Worker möglichst unmittelbar in die Auftragsbearbeitung einbezogen? Oder allgemeiner: Wie kann der Worker-Pool "atmen"?
- Wie werden User über Auftragsergebnisse (oder gar Fortschritte) informiert?
- Wie kann ein Spectator die Arbeit(sverteilung) beobachten?
- Müssen Aufträge nach Vergabe noch "gesichert" werden können, falls Worker noch nicht zu ihrer Verarbeitung gekommen sind?
- Wie können die Worker möglichst ortsunabhängig verfügbar gemacht werden?





 Alles beginnt dabei mit... Einfachheit. Wir brauchen heute nicht leistungsfähigere Technologien, sondern vor allem einfachere. Sonst bleiben zuviele Entwickler zurück. Sie haben nicht die Zeit, sich in Kompliziertes einzuarbeiten. Kommen die Aspekte Komponentenorientierung, Verteilung und Parallelität nicht zusammen, dann nutzen nur wenige das Potenzial, das in Multi-Core Prozessoren und dem universalen Internet steckt.
Alles beginnt dabei mit... Einfachheit. Wir brauchen heute nicht leistungsfähigere Technologien, sondern vor allem einfachere. Sonst bleiben zuviele Entwickler zurück. Sie haben nicht die Zeit, sich in Kompliziertes einzuarbeiten. Kommen die Aspekte Komponentenorientierung, Verteilung und Parallelität nicht zusammen, dann nutzen nur wenige das Potenzial, das in Multi-Core Prozessoren und dem universalen Internet steckt.