Buchhandel und Verlage sind nicht die Schnellsten, was neue Technologien angeht. Ideen aus meiner Sicht als Leser, was der stationäre Buchhandel tun kann, um nachzuziehen und sich zu erhalten, um für mich attraktiv zu bleiben, habe ich schon geäußert.
Für die Verlage gibt es natürlich auch Ideen. Hier nur eine, wie ein cooles Buch 2.0 aussehen könnte.
Das scheint mir Lesen auf der Höhe der Zeit. Wie krude ist dagegen ein Kindle-Book oder ein Hörbuch.
Bis Verlage solche Produkte herstellen, wird allerdings noch einige Zeit vergehen. Auch nicht alle heutigen Verlage werden das schaffen. Andere werden an ihnen vorbeiziehen und die Gunst der Leserschaft erringen. Die Schnellen fressen die Langsamen.
Einstweilen wäre ich ja schon zufrieden, wenn Verlage ganz selbstverständlich jedes Buch auch als eBook herausbrächten. Für Romane und Fachbücher fährt der Zug in diese Richtung langsam los. Bei Sachbüchern und Schulbüchern scheint mir da aber noch einiges im Argen zu liegen.
Case in point: Das Französich Lehrwerk Découvertes von Klett, mit dem nun meine Tochter in der 6. Klasse beginnt. Der Verlag bietet keine eBook-Version an. (Warum nur? Weil Kinder keinen Computer haben? Das Gegenteil scheint mir der Fall. Alle haben ein Handy, fast alle haben einen Computer zuhaus. Meine Tochter – naja, wie könnte es anders sein ;-) - sogar zwei und noch ein eigenes iPad.)
Ich möchte nun mit meiner Tochter einen erneuten Anlauf nehmen, Französich zu lernen – aber natürlich auf meine Weise. Das heißt ich werde die Vokabeln mithilfe von FlashCards Plus Pro auf iPad und iPhone lernen. Und ich werde das Lehrbuch auf dem iPad und iPhone studieren – ob der Verlag das will oder nicht.
Wie das? Er bietet doch kein eBook an.
Ganz einfach mit roher Gewalt :-)

Bauanleitung – Aus einem Papierbuch wird ein eBook
Wenn der Verlag es nicht schafft auch nur das einfachste eBook herzustellen, dann schaffe ich das halt selbst: mit einem Teppichmesser, ScanSnap S1500, Abbyy FineReader, iPhone, pdfasm, Dropbox und GoodReader.
Schritt 1: Ich zerschneide das Lektionsbuch und das Grammatik-Beiheft mit dem Teppichmesser.

Schritt 2: Ich scanne die Seiten mit ScanSnap “Schnappi” S1500. Ein Hoch auf das papierlose Büro! Das Resultat sind PDF-Dateien. Da die Seiten als Bilder gescannt wurden, sind die Dateien natürlich sehr groß. 30 KB für 76 Seiten Grammatik-Beiheft. Deshalb zerlege ich das Lektionsbuch in Blöcke (Kapitel 1-3, Vokabeln + Index usw.).

Schritt 3: Ich lasse die Abbyy FineReader als OCR Texterkennung über die PDFs laufen, damit aus den Bildern echte Texte werden und ich in den PDFs suchen und markieren kann. (Abbyy liegt übrigens dem “Schnappi” bei.)

Schritt 4: Ich fotografiere noch einige Seiten des Lektionsbuches mit dem iPhone, die ich nicht durch den Scanner schieben konnte. Ist halt ein Hardcover, das Schulalltag standhalten muss. Die Photo-App meiner Wahl: Camera+

Schritt 5: Ich bündele einige PDFs mit den fotografierten Seiten, damit der Look hübsch einheitlich ist. pdfasm ist mein Freund – auch wenn die Bedienung etwas intuitiver hätte sein können. Da waren wieder mal Techniker die Gestalter der Benutzeroberfläche.

Schritt 6: Ich lege die PDFs in meine Dropbox, um von allen Devices (Laptop, iPad, iPhone) darauf zugreifen zu können. (Hoppla, aufpassen, damit die PDFs nicht ins öffentliche Verzeichnis geraten und ich durch Unachtsamkeit einen Link darauf in die Welt sende, auf dass auch noch andere Schüler, Eltern, Lehrer ein elektronisches Découvertes in die Hand bekommen.)

Schritt 7: Schließlich werfe ich den GoodReader auf dem iPad an, um mit der Lektüre der ersten Lektion zu beginnen.

Zeitaufwand für diese Aktion? Hm… ich habe es nicht gestoppt, aber ich schätze mal, dass es in Summe 2 Stunden gedauert hat. Zeitaufwendig war dabei allerdings nur die Texterkennung. Hat mich aber nicht gestört. Abbyy hat ja still vor sich hingepusselt im Hintergrund, während ich am Rechner weiterarbeiten konnte.
Fazit
Das war gar nicht so schwer. Den Verlag hätte es kaum mehr Aufwand gekostet bei besserem Ergebnis (kleinere PDFs, weniger Stückelung des Inhalts). Der hat den ganzen Content ja in Quark Xpress oder so und könnte ihn ganz leicht nach PDF exportieren.
Warum tut man das nicht? Ich kann nur einen Grund erkennen: ängstliche Unsicherheit. “Oh, mein Gott, was alles passieren könnte, wenn erstmal so ein PDF auf einer CD – nein, zu teuer! – oder im Internet auf unserer Homepage verfügbar wäre. Kriminelle Kinder könnten es verbreiten! Unsere Schulbuchverkaufe würden ins Bodenlose fallen. In 2 Jahren wären wir pleite. Arrghhhh! Das darf nicht passieren!” (Besonders verständlich ist so eine Denke natürlich bei Schulbuchverlagen, die garantierte Verkäufe dadurch haben, dass ihre Lehrwerke verbindlich durch Schulen oder Eltern in Papierform angeschafft werden müssen.)
So stelle ich mir die Verlagsredaktion vor – bis mir jemand plausibel macht, dass es ganz andere, mir als Leser total verständliche Gründe gibt, meine Lesegewohnheit nicht zu bedienen, obwohl es technisch möglich ist. Wenn dies also ein Verlagsmitarbeiter lesen sollte, möge er mich über solche Gründe bitte ins Bild setzen.
 Nun, gut: Wie ich festgestellt habe, kann mir das Verhalten der Verlage ziemlich egal sein. Mit relativ wenig Aufwand habe ich mir mein eBook in “good enough” Qualität selbst hergestellt. Nächstes Mal mache ich das mit meiner Tochter zusammen. Daraus wird dann ein kleiner Event, die jährliche “School Book Slashing Party” oder so :-) (Vielleicht eine Anregung für Pädagogen, um Kindern eine Möglichkeit zum Ausagieren von Aggressionen zu bieten? Mit Teppichmessern auf Schülbücher statt auf Mitschüler oder später Flugzeugpiloten?)
Nun, gut: Wie ich festgestellt habe, kann mir das Verhalten der Verlage ziemlich egal sein. Mit relativ wenig Aufwand habe ich mir mein eBook in “good enough” Qualität selbst hergestellt. Nächstes Mal mache ich das mit meiner Tochter zusammen. Daraus wird dann ein kleiner Event, die jährliche “School Book Slashing Party” oder so :-) (Vielleicht eine Anregung für Pädagogen, um Kindern eine Möglichkeit zum Ausagieren von Aggressionen zu bieten? Mit Teppichmessern auf Schülbücher statt auf Mitschüler oder später Flugzeugpiloten?)
In jedem Fall habe ich schon ein zweites Buch geordert, das ich mit dem Teppichmesser und den anderen Werkzeugen in ein eBook transformieren werde. Diesmal ist es ein Philosophiebuch: Das Prinzip Verantwortung. Suhrkamp verweigert hier die Veröffentlichung als eBook. Ob man meint, eine Existenz als eBook sei einem solchen Inhalt oder dem Klassiker-Status nicht würdig? Hm…
Naja, mir egal. Das Teppichmesser liegt schon bereit. Bei dem Buch wird es auch einfacher. Ist ein Paperback. Vielleicht kann ich das sogar komplett in Text umwandeln.
Aber nun kommen erstmal Sie: Machen Sie mit bei der großen Buchtransformation! Welchen Titel “rippen” Sie, um ihm die ewige Jugend als eBook zu schenken?
 Spendieren Sie mir doch einen Kaffee, wenn Ihnen dieser Artikel gefallen hat…
Spendieren Sie mir doch einen Kaffee, wenn Ihnen dieser Artikel gefallen hat…











 FitNesse ist ein hübsches Framework für Akzeptanztests. Ist zwar Java-basiert mit seinem eigenen Web-Server, aber der Einsatz ist auch für .NET möglich. Gojko Adzic hat dazu schon vor längerer Zeit ein Buch geschrieben –
FitNesse ist ein hübsches Framework für Akzeptanztests. Ist zwar Java-basiert mit seinem eigenen Web-Server, aber der Einsatz ist auch für .NET möglich. Gojko Adzic hat dazu schon vor längerer Zeit ein Buch geschrieben – 






 Das Buch ist ein Symptom für eine Kultur oder auch nur Arbeitshaltung, in der man soviel "auf dem Zettel hat", dass man überhaupt ein ausgefeiltes System braucht, um es zu bewältigen. Es scheint geradezu eine Tugend zu sein, sich soviel aufzuladen, dass man sich nur mit modernen Hilfsmitteln organisieren kann. Eine Aufgabenliste, ein Kalender, eine Wiedervorlagemappe oder auch (im fortgeschrittenen Stadium) eine Assistenz reichen nicht mehr. Nein, es muss ein mehrdimensionales Verwaltungs- und Erinnerungssystem sein.
Das Buch ist ein Symptom für eine Kultur oder auch nur Arbeitshaltung, in der man soviel "auf dem Zettel hat", dass man überhaupt ein ausgefeiltes System braucht, um es zu bewältigen. Es scheint geradezu eine Tugend zu sein, sich soviel aufzuladen, dass man sich nur mit modernen Hilfsmitteln organisieren kann. Eine Aufgabenliste, ein Kalender, eine Wiedervorlagemappe oder auch (im fortgeschrittenen Stadium) eine Assistenz reichen nicht mehr. Nein, es muss ein mehrdimensionales Verwaltungs- und Erinnerungssystem sein.



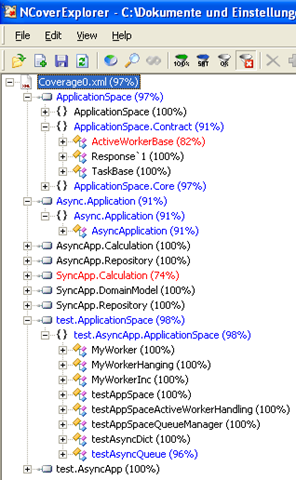
 Das hört sich viel an. Oder zumindest ungewohnt. Schon bei 3 Komponenten kommen 5 oder 6 Assemblies zusammen, wie die nebenstehenden Beispielanwendung zeigt. Und größere Anwendungen bestehen schonmal aus 50 oder 100 Komponenten und damit 100 oder 200 Assemblies.
Das hört sich viel an. Oder zumindest ungewohnt. Schon bei 3 Komponenten kommen 5 oder 6 Assemblies zusammen, wie die nebenstehenden Beispielanwendung zeigt. Und größere Anwendungen bestehen schonmal aus 50 oder 100 Komponenten und damit 100 oder 200 Assemblies. Doch auch wenn es keinen "materiellen" Nachteil hunderter Assemblies für eine Anwendung gibt, verstehe ich, dass sie dazu angetan ist, den Überblick zu verlieren. Vor allem wollen Sie womöglich dem Kunden gegenüber solche Detailfülle nicht offenlegen. Die Abbildung rechts zeigt, wie ich die Beispielanwendung eigentlich ausliefern müsste: als "Sack von Assemblies". Das ist zwar einfach, aber mag sich eben zumindest merkwürdig anfühlen.
Doch auch wenn es keinen "materiellen" Nachteil hunderter Assemblies für eine Anwendung gibt, verstehe ich, dass sie dazu angetan ist, den Überblick zu verlieren. Vor allem wollen Sie womöglich dem Kunden gegenüber solche Detailfülle nicht offenlegen. Die Abbildung rechts zeigt, wie ich die Beispielanwendung eigentlich ausliefern müsste: als "Sack von Assemblies". Das ist zwar einfach, aber mag sich eben zumindest merkwürdig anfühlen.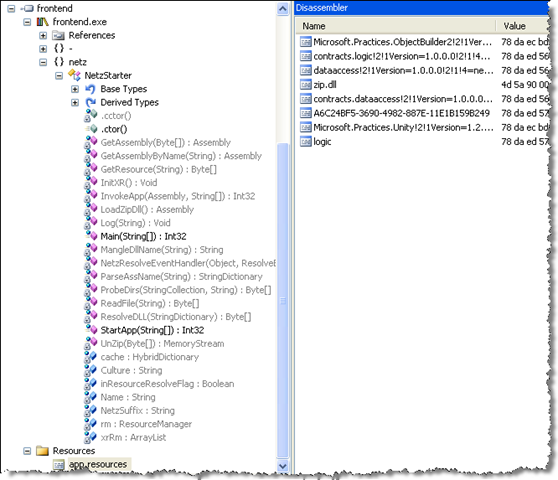
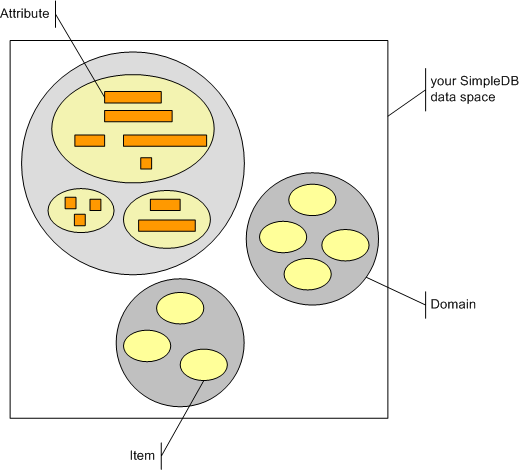
 NETZ kann aber noch mehr! NETZ kann die Assemblies auch in externe Ressourcen verpacken. So können Sie sie beliebig gruppieren. Auf die Referenzen hat das keinen Einfluss. Bilden Sie also beliebige Gruppen von Assemblies. Die Beispielanwendung habe ich z.B. einmal so zusammengefasst wie rechts zu sehen. In frontend.exe steckt die ursprüngliche EXE mit den Microsoft Unity DI Infrastruktur-Assemblies. Die contracts-Ressourcen enthalten die Kontrakt-Assemblies, die components-Ressource die Implementationen. Ganz einfach ist damit einem Batch wie diesem:
NETZ kann aber noch mehr! NETZ kann die Assemblies auch in externe Ressourcen verpacken. So können Sie sie beliebig gruppieren. Auf die Referenzen hat das keinen Einfluss. Bilden Sie also beliebige Gruppen von Assemblies. Die Beispielanwendung habe ich z.B. einmal so zusammengefasst wie rechts zu sehen. In frontend.exe steckt die ursprüngliche EXE mit den Microsoft Unity DI Infrastruktur-Assemblies. Die contracts-Ressourcen enthalten die Kontrakt-Assemblies, die components-Ressource die Implementationen. Ganz einfach ist damit einem Batch wie diesem: