Um es gleich vorweg zu sagen: Ich find WCF schon toll. Aber - und dieses aber ist mir wichtig - WCF lässt in mir kein Gefühl von "angekommen sein" entstehen.
Toll an WCF ist die Vereinheitlichung, die es erreicht hat. COM+/Enterprise Services, .NET Remoting, Web Services und MSMQ sind in WCF zu einem konsolidierten Programmier- und Kommunikationsmodell zusammengeflossen. Äußerlich ist der Unterschied zwar marginal - es werden wie seit der Erfindung von RPC immer noch entfernte Funktionen direkt aufgerufen. Doch die konsequente Nachrichtenorientierung ist der Natur entfernter Kommunikation wesentlich angemessener als die bisherigen Versuche der Objektorientierung, ihren Siegeszug bei der in-process Kopplung von Codeeinheiten auch auf die cross-process oder gar cross-platform Kopplung auszudehnen. Corba, EJB, .NET Remoting heißen diese letztlich gescheiterten Versuche. RIP.
Also: WCF ist toll. Und doch...
Es will sich bei mir kein wohliges Gefühl der Zufriedenheit einstellen. Die Vereinheitlichung ist mir irgendwie nicht genug. Vereinheitlichung war zwar ein wichtiges Ziel, ebenso der konsequente Abschied von "verteilten Objekten" - aber ist WCF deshalb gleich das Ideal? WCF ist vielleicht der beste vereinheitlichte nachrichtenorientierte API, den es gibt. Aber wollen wir eigentlich Nachrichtenorientierung? Ist funktionsbasierte Nachrichtenorientierung als einziges Kommunikationsmodell zwischen verteilten Codeeinheiten wirklich das wünschenswerte Abstraktionsniveau?
Ich werde das Gefühl nicht los, dass "es" noch anders gehen könnte und sollte. Zumindest als Alternative, wenn nicht als pauschaler Ersatz für WCF. Um das Gefühl mal zu konkretisieren, hier einige Punkte, die mir bei WCF aufstoßen. Lobeshymnen hören wir ja häufig genug. Also:
- WCF ist unehrlich
- WCF ist anti-autonom
- WCF ist kompliziert
- WCF ist starr
- WCF ist unintuitiv
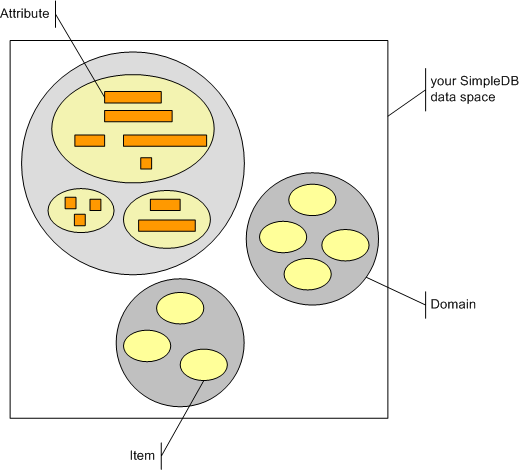
So ganz allein stehe ich mit meiner Meinung, dass WCF bzw. allgemeiner die Nachrichtenorientierung irgendwie noch nicht das Ende der Fahnenstange sein kann, wohl auch nicht. Das renommierte Portal "The Service Side" (TSS) hat gerade ein "Space Based Architecture Knowledge Center" eingerichtet und Amazon hat unlängst einen Tuple Space (SimpleDB) als Beta in sein SaaS-Angebot gehoben. (Mehr zum Thema SimpleDB in bei meinem Open Source Projekt NSimpleDB.)
Spaces - so die Botschaft von TSS (mithilfe des Infrastrukturanbieters Gigaspaces) und Amazon - sind eine Alternative zur Nachrichtenorientierung. Spaces und Räume statt der ewigen Röhren. Warum nicht? Dem Gedanken bin ich sehr zugetan. Deshalb bastle ich mit an einem "Space-Angebot" - das aber noch eine Weile bis zum großen Auftritt brauchen wird. Deshalb habe ich das SimpleDB Datenmodell mit NSimpleDB auf den Desktop gebracht, um es leichter für Experimente verfügbar zu machen. Denn Experimente sind noch nötig, um die Reichweite des Space-Paradigmas abzustecken. In dieser Linie sehe ich auch dieses Posting: Als ein lautes Nachdenken über Space Based Architecture (SBA) oder Space Based Computing (SBC) oder Space Based Collaboration (SBC), mit dem ich mir selbst wieder ein Stückchen klarer über Nutzen und Grenzen von SBC/SBA werde. Ein probater Anfang ist dafür wie immer, mal die "pain points" zu benennen, wo mich das Existierende sticht.
WCF ist aus meiner Sicht unehrlich, weil ich die Syntax des Methodenaufrufs für das falsche Mittel halte, um einen Auftrag an eine entfernte Codeeinheit zu übermitteln. Einer Anweisung wie
resp = service.TueEtwas(req);
kann ich nicht ansehen, ob der Service lokal oder remote läuft. Läuft er aber remote, dann leistet die Syntax den vielzitierten "Fallacies of Distributed Computing" massiven Vorschub. Das halte ich für essenziell nachteilig im Hinblick auf Wartbarkei und Verständlichkeit und womöglich auch Skalierbarkeit und Performance. Ausführlich habe ich diesen Gedanken in einem Beitrag [PDF] für "SOA Expertenwissen" dargelegt.
In dem Beitrag erkläre ich auch, warum diese Form der "Auftragsübermittlung" für mich grundlegend anti-autonom ist. Sie formuliert einen Befehl, dessen syntaktische Form danach heischt, sofort ausgeführt zu werden. Sofortigkeit steht jedoch zum Einen im Widerspruch zur physikalischen Realität der Verteilung von Client und Service, zum Anderen ist sie aber auch unvereinbar mit dem simplen Hauptgrund einer Verteilung überhaupt: Autonomität. Verteilte Codeeinheiten sind verteilt, damit sie möglichst autonom über ihre Prozesse und Ressourcen entscheiden können. Wer jedoch autonom ist, der will sich nicht vorschreiben lassen, wann und wie genau er einen Dienstleistungswunsch erfüllt. Solchen Freiraum bietet die Form der Nachrichtenorientierung in WCF jedoch nicht.
Nun mag man das alles für Haarspalterei halten. Das fände ich zwar schade, weil Form und Funktion, Syntax und Semantik in einem Gleichklang stehen sollten. Wenn sich die Funktionsweise in der Form widerspiegelt, wenn klar erkennbar ist, wie etwas funktioniert, dann ist das Bild kohärent und wirkmächtiger. Dann ist weniger Raum für Missverständnisse.
Aber sei´s drum. Deshalb hier zwei hoffentlich handfestere Kritikpunkte: Ich finde WCF recht einfach für Allereinfachstes, aber kompliziert für sehr Typisches. Typisch sind für mich z.B. die asynchrone Benachrichtigung über Ereignisse in einem Service, typisch sind für mich daraus folgende Aufrufe des Service. Beides ist natürlich mit WCF möglich. Aber ich finde es recht kompliziert. Für eine simple Notifikation muss ich plötzlich über Duplexkommunikation nachdenken und ein Rückrufinterface registrieren. Und wenn ich dann in so einem Event den Service aufrufen möchte, dann geht es plötzlich um Reentrancy. Das kann man alles lernen. Klar. Aber das ist so typisch, dass ich den Lernaufwand und damit die Gefahr, etwas falsch zu machen, für zu groß halte.
Kompliziert wird es auch, wenn meine Services nicht (nur) an einer Adresse zu erreichen sind. WCF verlangt ja, dass ich die Adresse einer Dienstleistung festlege. Das finde ich starr. Reicht das starre Schema aber nicht, weil ich Mobilität oder Fehlertoleranz haben möchte, dann muss ich Klimmzüge machen oder gar orthogonal zu WCF mit Infrastruktur wie Clusterservern anfangen. Geht alles - aber könnte einfacher sein, finde ich.
Kollaboration statt Kommandoton
Schließlich: Mit WCF kann ich Nachrichten zwischen zwischen Parteien austauschen. Aber ist das Leben denn immer Nachrichtenaustausch, direkter Nachrichtenaustausch? Wer gewohnt ist, im Kommandoton zu sprechen und sofortige Ausführung erwartet, der ist mit Nachrichtenaustausch von oben nach unten in der Befehlshierarchie sicherlich zufrieden. Doch selbst das Militär hat inzwischen erkannt, dass sich mit Gehorsam allein kein Krieg gewinnen lässt. Krieg und Geschäftsleben, beide sind so dynamisch, dass autonome Entscheidungen ohne expliziten Befehl ganz vorne an der Front wichtig sind. Und Kriegsführung wie Geschäftsführung setzen daher auf Kollaboration statt Kommandoton, wenn´s darauf ankommt, wirklich etwas gebacken zu bekommen.
Kollaboration, d.h. selbstständige Zusammenarbeit an etwas Gemeinsamem, ist auch die natürlichste Arbeitsform. Dabei zwingt nicht der eine Kollaborateur den anderen, ihm - hopp! - einen Dienst zu leisten, sondern wünscht sich das sozusagen indirekt. In der Kollaboration ist Asynchronizität der vorherrschende "Antwortmodus" und Aufgaben werden "ausgeschrieben". Kollaborateure stehen um ein (mehr oder weniger handfestes) Medium herum, auf das sie gemeinsam blicken. Das kann ein Arbeitsplan sein, eine Geländekarte, eine Bauwerk, ein Tisch voll mit CRC-Cards, eine Inbox auf dem Schreibtisch oder auch ein Spielbrett. An diesem Medium arbeiten die Kollaborateure gemeinsam, damit bzw. daran teilen sie sich Aufgaben zu. Jeder behält dabei seine Autonomität, beobachtet das gemeinsame Medium, manipuliert das gemeinsame Medium. Und die von allen anerkannten Regeln, wie mit dem Medium umgegangen werden darf, sorgen dafür, dass die Kollaborateure trotz ihrer Autonomität einem gemeinsamem Ziel zustreben.
Also: Wo die Aktivitäten von autonomen Einheiten koordiniert werden sollen, geschieht das oft über einen "runden Tisch", ein gemeinsames Medium, um das sich alle versammeln. Da WCF nun eine Technologie ist, die die Zusammenarbeit von Codeeinheiten befördern will, liegt deshalb die Frage nahe, ob WCF jenseits des Kommandotons entfernter Serviceaufrufe auf die Kollaboration mittels gemeinsamen Mediums beherrscht? Die Antwort lautet nein. Für WCF ist die Arbeit an gemeinsamen Datenstrukturen kein Thema. Und genau das halte ich für ein großes Manko. Das macht WCF nämlich unintuitiv für den Einsatz in vielen Verteilungsszenarien. Schon ein simpler Chat oder ein verteiltes Spiel sind dafür gute Beispiele: Chat und Spiel (z.B. TicTacToe) sind triviale Kollaborationsaufgaben, bei denen die Beteiligten an einfachen Datenstrukturen gemeinsam arbeiten. Beim Chat ist das eine Liste von Nachrichten, beim Spiel ein zweidimensionales Array (Spielfeld). Von einer Technologie, die die Entwicklung verteilter Anwendungen erleichtern will, erwarte ich nun, dass sie mich auch unterstützt, diese natürliche Sichtweise im Code abzubilden. Das tut WCF aber nicht. Für WCF gibt es keine gemeinsame Liste, kein gemeinsames Spielfeld. WCF sagt: "Sieh zu, wie du es mit gegenseitig zugerufenen Befehlen hinbekommst, dass jeder Beteiligter denkt, es gäbe die gemeinsame Datenstruktur."
Das ist natürlich absolut legitim. Wenn WCF sich mit gemeinsamen, verteilten Datenstrukturen nicht abgeben will, dann ist das eine klare Aussage. Aber es bleibt dadurch eben auch eine Lücke. Manche oder womöglich eine ständig wachsende Zahl von Anwendungen haben es trotz WCF schwer. Bei ihnen geht es "nur" um Kollaboration und gleich eine Datenbank als gemeinsame Struktur aufzusetzen, wäre für sie Overkill. Kollaborationsinformationen sind oft nur kurzzeitig relevant.
Mit mehr Abstraktion in die Zukunft
Für mich ergibt sich damit ein "Wunschbild" wie folgt:
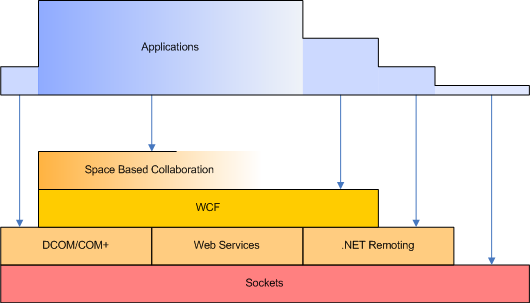
Der Stack der Kommunikationstechnologien wäschst weiter. Muss weiter wachsen. Alte Technologien werden nicht einfach ersetzt, sondern in der Relevanz nur zurückgedrängt. Es wird weiterhin Anwendungen geben, die direkt via Sockets kommunizieren müssen. Und das ist ok. Auch wird es Szenarien geben, in denen .NET Remoting Stärken gegenüber WCF ausspielt, d.h. entfernte Objekte gegenüber der Nachrichtenorientierung einfach Abstraktionsvorteile bieten. Und warum auch nicht? Nachrichtenorientierung mit WCF wird natürlich auch ihren Platz haben. Keine Frage. Aber ich glaube, Nachrichtenorientierung tut gut daran, ihren Alleinherrschaftsanspruch über die Kommunikation in verteilten Anwendungen aufzugeben. Nachrichtenorientierung ist nicht das Gipfelkreuz auf dem Abstraktionsberg, sondern allenfalls ein Lager in großer Höhe.
Und was kommt nach bzw. oberhalb von WCF? Mein Tipp: Space Based Collaboration. Spaces sind nach 20 Jahren Forschung und kommerziellen Anläufen reif für die breite Masse. Performance und Netzwerkverfügbarkeiten sind hoch genug, um ihre Ansprüche befriedigen zu können. Abstraktion kostet ja immer etwas.
Aber Abstraktion bringt vor allem immer etwas: weniger Kopfschmerzen. Das halte ich für erstrebenswert. WCF ist gut und notwendig. Aber verteilte Anwendungen der unterschiedlichsten Art und Größe - von cross-thread Kommunikation bis global cross-platform Kommunikation - dürfen gern noch viel einfacher zu bauen sein. Spaces bieten da, meine Meinung nach, ein schönes und überfälliges Daten-/Programmiermodell. Denken in Räumen und Datenstrukturen, statt in Nachrichten und Röhren.
Tuple Spaces, JavaSpaces, GigaSpaces, SimpleDB... das ist erst der Anfang. Stay tuned!


 Das gute, alte Papier hat mich wieder.
Das gute, alte Papier hat mich wieder.
 Neulich hat es mich auch überkommen und ich habe endlich auch das
Neulich hat es mich auch überkommen und ich habe endlich auch das  Die ACM-Hauszeitschrift "Communications of the ACM" bringt mir jeden Monat einen bunten Blumenstrauß an Themen ins Haus, die ich in den anderen sehr praxislastigen Publikationen nicht finde.
Die ACM-Hauszeitschrift "Communications of the ACM" bringt mir jeden Monat einen bunten Blumenstrauß an Themen ins Haus, die ich in den anderen sehr praxislastigen Publikationen nicht finde.



 Um dann aber eine Publikation von mehreren Seiten wirklich zu lesen, brauche ich Papier. Ja, immer noch. So sehr ich ein Freund von online Publikationen bin (ich schreibe ja immerhin auch dieses Block), so ist das Lesen von Publikationen immer noch etwas anderes.
Um dann aber eine Publikation von mehreren Seiten wirklich zu lesen, brauche ich Papier. Ja, immer noch. So sehr ich ein Freund von online Publikationen bin (ich schreibe ja immerhin auch dieses Block), so ist das Lesen von Publikationen immer noch etwas anderes. So, jetzt aber genug für heute. Die Abos sind bestellt... Upps, eines habe ich noch vergessen
So, jetzt aber genug für heute. Die Abos sind bestellt... Upps, eines habe ich noch vergessen