
Alles soll heute flexibel sein: Menschen, die sich auf Jobangebote bewerben, genauso wie Programmiersprachen. Statisch ist out, dynamisch ist in. Nur noch nicht so recht bei den Daten. Denn da regieren Strenge und Statik. Daten werden einmal in Klassen oder Tabellen verpackt - und dann ändert sich diese Anordnung am besten nicht mehr. Falls doch, muss solche Veränderung gut geplant sein, damit die fein ziselierten Datenstrukturen nicht inkonsistent werden.
Datenspeicherung gehört zu einer statischen Welt
Daten in Container zu verpacken, die einander referenzieren, ist eben ein Informationsmodell für statische Datenstrukturen. Die Daten mögen sich ändern, aber die Strukturen, die Zusammenhängen bleiben konstant. Das ist völlig ok. Allerdings dient das vor allem einem Zweck: der 1:1 Speicherung und Reproduktion von Daten. Das Mittel der Wahl ist dabei das Kopieren dieser Daten. Wenn Sie z.B. Personendaten bestehend aus Vorname+Nachname in einer Datenbank speichern, dann werden die Bytes von Vorname und Nachname mindestens einmal in der Datenbank unverändert abgelegt, wahrscheinlich jedoch mehrfach. Jeder Index multipliziert ja gespeicherte Daten.
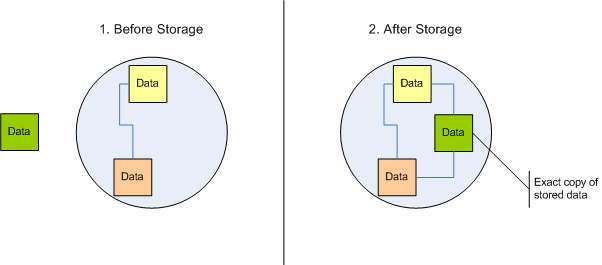
Dass die Geschichte der Softwareentwicklung sich bisher vor allem mit solcher Datenspeicherung beschäftigt hat, ist verständlich. Wenn man etwas mit Daten der äußeren Welt tun will, dann holt man sie am besten erstmal 1:1 "ins System". Mit einer Sprache wie SQL kann man sie dann bei Bedarf in Form von Views umarrangieren; allerdings funktioniert das nur in Maßen, denn SQL kann die grundsätzliche Container-Referenz-Dichotomie nicht aufheben.
Assimilierung für eine dynamische Welt
Seit der Geburt der relationalen Datenbanken sind nun aber einige Jahrzehnte vergangen. Die Welt hat sich verändert. Die Welt und damit die Anforderungen an die Datenbanken sind dynamischer geworden. Zusammenhänge, die gestern galten, sind morgen veraltet. Die auf Statik angelegten Datenstrukturen in heutigen Datenbanken sind somit kontraproduktiv. Sie sind wie Sand im Getriebe, wie Kalk in Gelenken.
Das Problem sind zum Einen die festen Containergrenzen, in die Daten in großen Blöcken eingepfercht sind. Denn Daten in Containern lassen sich nicht mit Daten in anderen Container in neue Beziehungen bringen. Nur Container selbst können einander referenzieren. Zum anderen sind Referenzen als Teil der Daten in Containern ein Problem. Solange Referenzen in Container stecken, müssen Containerstrukturen nämlich verändert werden, um neue Beziehungen herzustellen. Solche Schemaänderungen widerstreben dann zurecht jedem Datenbankadmin, denn sie widersprechen dem grundlegenden Paradigma der statischen Strukturen aller Container-Referenz-Datenmodelle.
Um nun Daten fit für eine dynamische Welt zu machen, muss also das Datenspeicherparadigma aufgegeben werden. In einer dynamischen Welt ist nicht mehr die 1:1 Speicherung und Reproduktion von Daten der Hauptzweck von Datenbanken. Die Reproduktion von Datenstrukturen ist nicht mehr der Rede wert; sie ist selbstverständlich.
Der Hauptzweck der Datenverarbeitung ist heute vielmehr die Flexibilisierung von Daten. Sie müssen so gehalten werden, dass jederzeit neue Zusammenhänge zwischen ihnen hergestellt werden können. Daten müssen fähig werden zum Networking. Business Intelligence (BI) ist zwar schon eine Disziplin, die sich der Schöpfung von Werten aus neuen Zusammenhängen zwischen Daten widmet. Aber auch BI ist letztlich noch dem bisherigen Datenspeicherungsparadigma verhaftet.
Wahre Dynamik und maximale Flexibilität erreicht die Datenverarbeitung erst, wenn Daten nicht mehr gespeichert, sondern assimiliert werden. Denn Daten wie andere "Dinge" der realen Welt, sind immer nur so flexibel, d.h. "verformbar", wie sie aus "verschiebbaren" Einzelteilen bestehen.

Dynamik kommt also erst in die Datenhaltung, wenn wir Daten nicht mehr als zu festen Blöcken in erhaltenswerten Containern zusammengesetzt ansehen, sondern als "Säcke" voller "Datenatome". Was diese Datenatome dann sind, ist zunächst einmal egal. Es können einzelne Bits, einzelne Zahlen, einzelne Zeichenketten oder einzelne 2 MB Blobs sein. Je feiner die Granularität dieser "Atome", desto höher jedoch die Flexibilität des "Datensacks".
Und nicht nur das! Denn diese "Datenatome" können nicht nur innerhalb eines Sacks immer wieder neu arrangiert, sondern können maximal flexibel mit "Datenatomen" anderer Säcke in Beziehung gesetzt werden. Statt Datenblöcke also einfach nur 1:1 zu speichern, müssen wir sie "shreddern". Dann erhalten wir maximal verbindbare "Datenatome". Und diese "Datenatome" assimilieren wir in eine "Wolke" schon existierender "Datenatome".
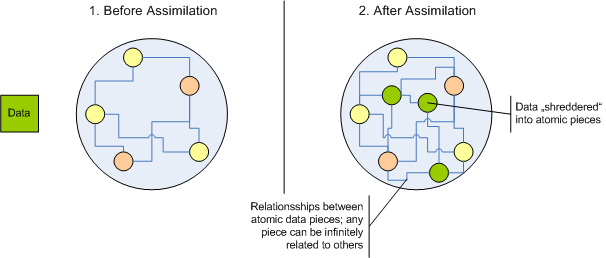
Assimilation besteht damit aus zwei Schritten:
- Datenblöcke in "Datenatome" zerlegen
- "Datenatome" mit schon vorhandenen vernetzen
Und der zweite Schritt kann sogar beliebig oft wiederholt werden! Per definitionem ist nicht zu befürchten, die Struktur der "Datenatome" je verändern zu müssen. Es sind ja Atome; aus Sicht einer Anwendung haben sie daher keine weitere, für zukünftige Beziehungen relevanten internen Strukturen.
Wo vorher noch Daten in Containern waren, sind nach der Assimilation die Container verschwunden und die Daten in eine "Datenwolke" (oder ist es eher ein "Datenplasma"?) aufgelöst und mit schon existierenden "Datenwolken" verschmolzen. Assimilation speichert Daten also nicht einfach, sondern löst sie in einem größeren Ganzen auf. Wie bei sonstigen Lösungen verschwindet das Aufgelöste jedoch nicht, sondern verteilt sich nur bzw. wird hier in das Vorherige integriert. Die ursprünglichen Daten sind also auch in der Gesamtheit alles Assimilierten noch enthalten - nur eben nicht klar umrissen an einem Ort wie die Datenkopien bei der üblichen Datenspeicherung. Dennoch lassen sich aus einem "Assimilat" auch wieder die ursprünglichen Daten in ihren Containern zum Zeitpunkt der Anlieferung regenieren.
Um Daten wahrhaft flexibel zu halten, müssen wir also das Operationenpaar Speichern/Laden durch das neue Paar Assimilieren/Regenerieren ersetzen. Dem bisherigen Grundanspruch der 1:1 Datenhaltung wird damit immer noch Rechnung getragen. Doch darüber hinaus eröffnet die assimilierende Datenhaltung ganz neue Möglichkeiten zur Vernetzung von Daten, zur Bildung immer neuer Zusammenhänge.
Assimilation ist die Grundlage für Synergieeffekte zwischen Daten. Durch Assimilation werden Daten so flexibel, wie sie eine immer dynamischer werdende Umwelt braucht.
Oder passend zum Jahresschluss: Speichern war 2007... Assimilation ist 2008.
2 Kommentare:
Hallo. Die Gedanken sind genial. So habe ich über das Thema Datenbanken und Datenspeicherung noch nicht nachgedacht.
Eine Frage habe ich aber: Wie willst du dieses Datenplasma speichern? Also werden die Daten wieder in Datenbanken abgelegt oder in XML-Dateien? Oder ist dafür eine neue Form der "Speicherung" nötig?
@k00ni: Ein Pile - wie beschrieben in meiner Artikelserie (1/08, 2/08) in der dotnetpro - ist eine Datenstruktur bzw. ein Informationsmodell, mit dem Daten assimiliert werden können.
Wie ein Pile dann implementiert ist, ist eine zweite Frage. Da können etablierte Technologien helfen. Am wichtigsten ist zunächst, dass wir einen frischen Blick auf die Daten werfen und sie nicht mehr als zu kopierende Blöcke ansehen, sondern als etwas zu shredderndes.
Kommentar veröffentlichen