
Das Intuitive Datenmodell (IDM) kennt nur ineinander geschachtelte Werte. Eine Intuitive Datenbank (IDB) ist damit ein großer Raum, in dem solche Werte gespeichert werden. Eine beschränkende Vorstrukturierung in Tabellen und Tabellenzeilen ist ihr fremd. Sie kennt nur ein Konzept: den schachtelbaren Wert.
Die Kommunikation mit einer IDB geschieht jedoch in "Happen", die ich einmal Dokument nenne. Jedes Dokument ist eine Ansammlung von Werten, die allerdings im Speichervorgang in das schon vorhandene Wertegeflecht eingewoben werden. Eine IDB nimmt ein Dokument also nicht wie eine RDB einfach in Form einer Kopie auf! In einer IDB existieren keine Daten mehr in Kopie. Eine IDB enthält Werte der "äußeren Welt" und insofern auch Kopien. Aber jeden Wert aus der äußeren Welt, der in einem oder vielen Dokumenten steckte, die einer IDB "dargeboten" wurden, enthält die IDB nur einmal.
Das Relationale Datenmodell (RDM) kennt natürlich im Grunde auch Datengeflechte. Sie werden durch die Beziehungen zwischen Datensätzen hergestellt. Dennoch hat für mich das Daten- bzw. Wertegeflecht des IDM noch eine andere Qualität. Im IDM können nämlich Daten nicht anders, als sich zu verflechten. Es passiert ganz automatisch. Im RDM müssen Sie das Geflecht sehr bewusst weben, indem Sie Beziehungen über Fremdschlüssel aufbauen. Im IDM hingegen "passieren" Beziehungen ganz von allein immer und notwendig überall dort, wo Dokumente dieselben Werte enthalten.
Da das IDM alle Werte nur einmal enthält - und das auf allen Strukturebenen von Dokumenten -, teilen sich Dokumente gleiche Werte automatisch. Gleiche Werte sind quasi die Schnittpunkte von Dokumenten. Hier zwei Dokumente, in denen derselbe Wert in unterschiedlicher Schachtelungstiefe vorkommt:
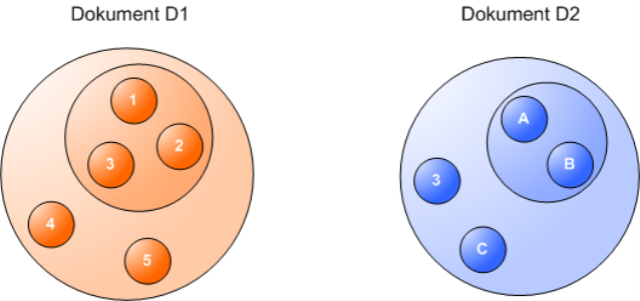
Aus Sicht des IDM schneiden sich diese Dokumente in dem Wert, der in beiden vorkommt. Sie überlappen in ihm, er gehört zu beiden Dokumenten gleichzeitig.
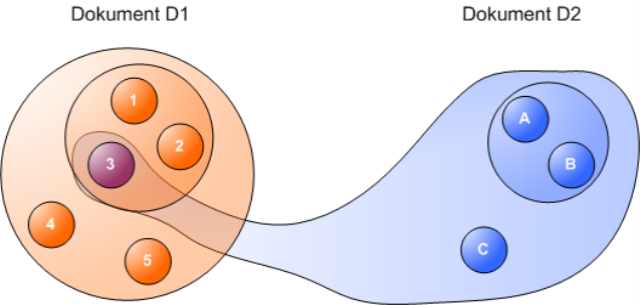
Einfacher ist dieses Schneiden von Dokumenten allerdings mit einem Baum darstellbar. Er führt zwar wieder Verbindungen zwischen Werten ein, aber die sollen nur Zugehörigkeit beschreiben. Sie definieren eine Enthalten-Beziehung wie die Zusammenfassung von Werten in den vorstehenden Bildern. Verwechseln Sie sie bitte nicht mit Referenzen im Objektorientierten Datenmodell (ODM) oder Fremdschlüsseln des RDM.
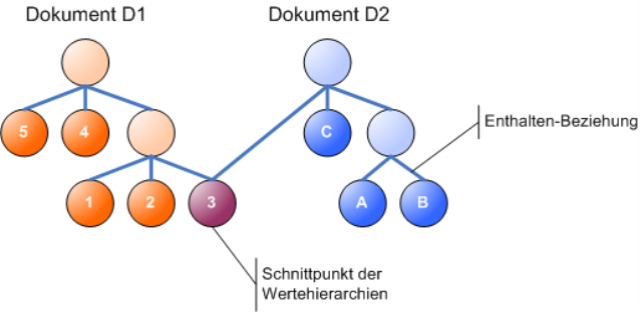
Dokumente können eine beliebige Anzahl solcher Schnittpunkte haben. Enthält ein Dokument mehrfach denselben Wert, so schneidet es sich sogar mit sich selbst.
Für das Verständnis des IDM ist es zentral, den Effekt dieser Dokumentenschnitte zu verstehen. Sie führen dazu, dass sich in einer IDB nicht einfach eine Anzahl nebeneinanderliegender Dokumente anhäuft, sondern alle Dokumente zusammen ein großes Ganzes ergeben. Alle Dokumente sind miteinander verwoben, ohne dass dafür etwas Spezielles getan werden müsste.
Auch sehr Verschiedenes berührt sich dort, wo es Gleiches enthält. Das ist wie im richtigen Leben: Die vorstehende Grafik enthält einen Baum und lässt damit diesen Text mit einem Wald in Verbindung treten. So unterschiedliche Zusammenhänge wie Software und Natur berühren sich im Begriff Baum. Diese Berührung haben Sie und ich nicht geplant, sie entsteht einfach in Ihrem und meinem Kopf durch Verwendung desselben Begriffs hier wie dort.
Im richtigen Leben begrüßen wir solche spontanen Überschneidungen von ansonsten ganz Verschiedenem. Wir versuchen sogar, sie mit Kreativitätstechniken zu befördern. Wem solche Assoziationen leicht fallen, wird gewöhnlich beneidet. Sie sind ein Merkmal von Intuition, wenn sie denn irgendwann bewusst werden. Wannimmer wir ausrufen, "Ach, das erinnert mich an..." oder "Das ist genauso wie bei...", dann sprechen wir über einen solchen Schnittpunkt von Kontexten. Natürlich kann das umso häufiger passieren, je mehr "Weltwissen" wir haben, je aufmerksamer wir beobachten. Jeder Schnittpunkt ist dann ein Brückschlag und lässt uns etwas Neues erkennen.
Analogien sind in diesem Sinne bewusste Brückenschläge, um Zusammenhänge zwischen ansonsten Unverbundenem herzustellen, um Eigenschaften eines Kontexts mit denen eines anderen in Beziehung zu setzen.
Genauso ist es im IDM: Indem Dokumente sich automatisch in jedem übereinstimmenden Wert schneiden, werden immer wieder Verbindungen zwischen ansonsten Unverbundenem hergestellt. Es können und sollen sich Assoziationen ergeben, die quasi unplanbar sind. Dieser Effekt ist natürlich umso größer, je mehr Dokumente in eine IDB aufgenommen werden und je vielfältiger sie sind.
Anders als beim ODM/RDM ist für die Verbindung der Dokumente jedoch viel weniger Planungsaufwand zu treiben. Niemand muss sich hinsetzen und Verbindungen im Sinne von Container-Referenzen planen. Sie ergeben sich vielmehr einfach so im Verlauf der Aufnahme von immer mehr Dokumenten in einen IDM-Werteraum. (Die Diskussion, wie man die Assoziation von Dokumenten durch etwas Planung befördern kann, möchte ich auf einen zukünftigen Artikel vertagen.)
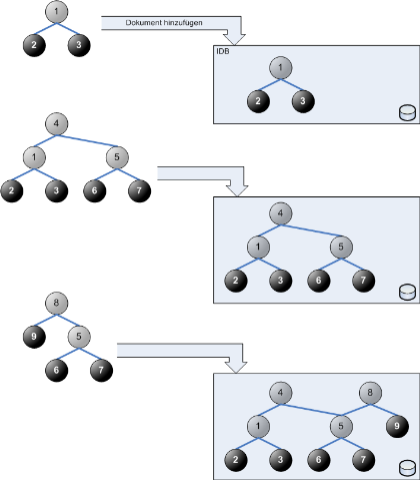
Bild anklicken zur Vergrößerung
Das Endresultat der Aufnahme von immer mehr Dokumenten in eine IDB ist ein großes Dokument, dem man nicht mehr ansehen kann, in welcher Reihenfolge seine Teile hinzugefügt wurden. Auch die ursprüngliche Granularität der darin eingegangenen Dokumente ist nicht mehr erkennbar. Aufgenommene Dokumente verlieren sozusagen ihre Identität. Sie werden einfach Teil eines größeren Ganzen; sie werden assimiliert wie Menschen von den Borg bei Star Trek.
Diese Assimilation ist kommutativ und idempotent:
- Sie kann in beliebiger Reihenfolge stattfinden und führt immer zum selben Ergebnis. Dokument A + Dokument B führt genauso zu "Gesamtdokument" C wie B + A.
- Dasselbe Dokument kann beliebig oft assimiliert werden: A + B = C, aber auch A + B+ B = C oder A + A + B = C.
4 Kommentare:
Ich stimme Dir bei den grundsätzlichen Aussagen zur Container-Dichotomy zu.
Was die Überlappung von Mengen angeht könnte man es auch etwas mehr aus der Praxis beschreiben.
Angenommen man hat zwei Objekte shop und color. In shop seien z.B. Daten eines Online-Shops gespeichert. In color seien alle Farben des Internetauftritts gespeichert. Nun soll es den Fall geben, dass der Shop eine Farbe zugewiesen bekommt. Nur welchem Objekt soll man es zuordnen? Entweder schreibt man shop.color oder color.shop. Das ist das Dilemma. Derselbe Wert muss in zwei unterschiedlichen Objekten liegen. Lösung: die Objekte müssen sich überschneiden können!
@Anonym: shop.color und color.shop sind beide legitime pfade durch die daten. "überschneidung" sind im intuitiven datenmodell absolut ok, nein, sogar zentral. es liegt also kein dilemma vor, sondern ein feature :-)
-Ralf
Vielleicht habe ich mich missverständlich ausgedrückt. Ich meinte das Dilemma, das man deswegen bei der Container-Dichotomy hat. Man muss sich dort immer für einen Container entscheiden. Hab's an einem praktischen Beispiel verdeutlicht. Ist vielleicht für manchen anschaulicher, als eine abstrakte Mengendarstellung.
Dass es im intuitiven Datenmodell zentral ist, ist mir klar. Und nur deswegen weil diese "Überschneidungen" im intuitiven Datenmodell möglich sind bin ich hier auf den Seiten. Bin übrigens über einen Link von Pile Systems hierher gelangt.
Ich befasse mich schon seit einiger Zeit mit demselben Phänomen. Habe auch einen Prototypen solch einer Datenbank in Perl geschrieben. Mathematisch war ich von einer anderen Seite her draufgestossen (Stichwort: Permutationen). Daher fand ich es interessant die Sache noch aus einem anderen Blickwinkel zu sehen. Wenn Interesse besteht könnten wir uns per Mail oder ICQ über die Sache unterhalten.
@Anonym: Wir können uns gern darüber per Mail unterhalten. Meine Adresse findest du im Impressum meiner Homepage www.ralfw.de.
-Ralf
Kommentar veröffentlichen